背景
在AI大爆发的时代,已经有非常多的AI助手,结合RAG通过智能问答帮助用户解答问题。单纯地依靠智能问答帮助客户自助解答是远远不够的,我们需要让AI助手能够直接调用存量且丰富的管控或者其他接口,朝着更强大的智能体演进。我们选用当下最为火热,且已逐步成为标准的MCP作为模型和接口之间通信的传输协议。关于MCP,已有非常多的介绍文章,本文不再赘述。
在企业对外服务的场景下,MCP Server必要需要解决以下几个问题:
(1)在服务的多实例高可用场景下,使用SSE通信方式如何维护session;
(2)如何做到动态更新MCP工具Prompt,做到快速更新&调试&验证;
(3)租户隔离的云服务场景下如何对用户的工具调用进行鉴权。
Higress可以很好地解决上面的问题1,同时还有完善的运维监控体系,可视化易操作的控制台界面。为了解决问题2,我们引入了Nacos负责注册后端服务以及管理维护MCP工具的元数据等信息。在整个MCP服务中,Higress担任MCP Proxy的角色,Nacos担任MCP Registry的角色。对于问题3租户隔离问题,会在下面鉴权章节中进行详细说明。
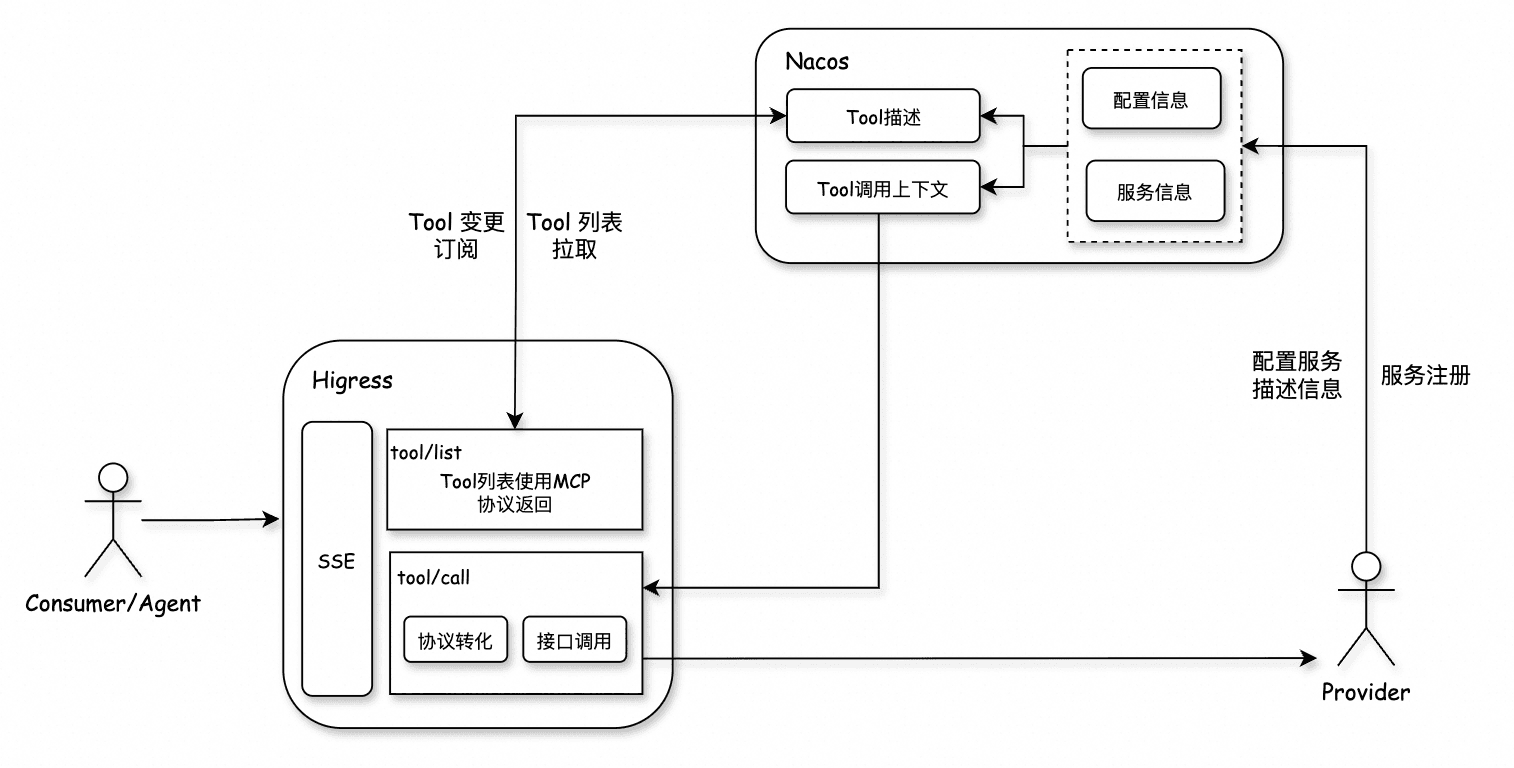
Higress和Nacos都是云原生的应用,在部署方面,自然选择使用K8s集群进行云原生部署。同时很多企业有自己的专属生产网络环境,一般和外网不通,因此本文会围绕如何利用社区版本的Higress和Nacos(Apache-2.0开源协议)进行私有化部署。因为内部环境的限制,我们没有办法直接通过Helm操作K8s集群进行部署,因此本文会围绕如何基于Higress和Nacos的docker镜像在K8s集群上进行分角色部署。
通过这套自建的网关服务,使用配置即可实现零代码扩展Tool,新应用的注册、应用下面工具的扩展、工具prompt更新验证都能通过服务集成的可视化控制台,更新发布配置快速完成,接入方式极其简单!更新验证极其快速!同时利用Nacos的命名空间能力可以做到服务和工具集的隔离,给不同的用户提供不同的MCP工具集。
私有化部署
Higress
Higress支持三种部署方式:Helm、docker compose和基于all-in-one的docker镜像进行部署。Higress官方推荐使用Helm的方式进行生产环境的部署,将依赖的模块部署在不同的pod上。而因上述环境原因,这里选择使用第三种基于all-in-one的docker镜像[Dockerfile]进行部署,将Higress依赖的组件以进程的方式部署在同一pod上面,通过多副本的方式实现服务高可用,也实现了对K8s集群Ingress的无侵入式部署。
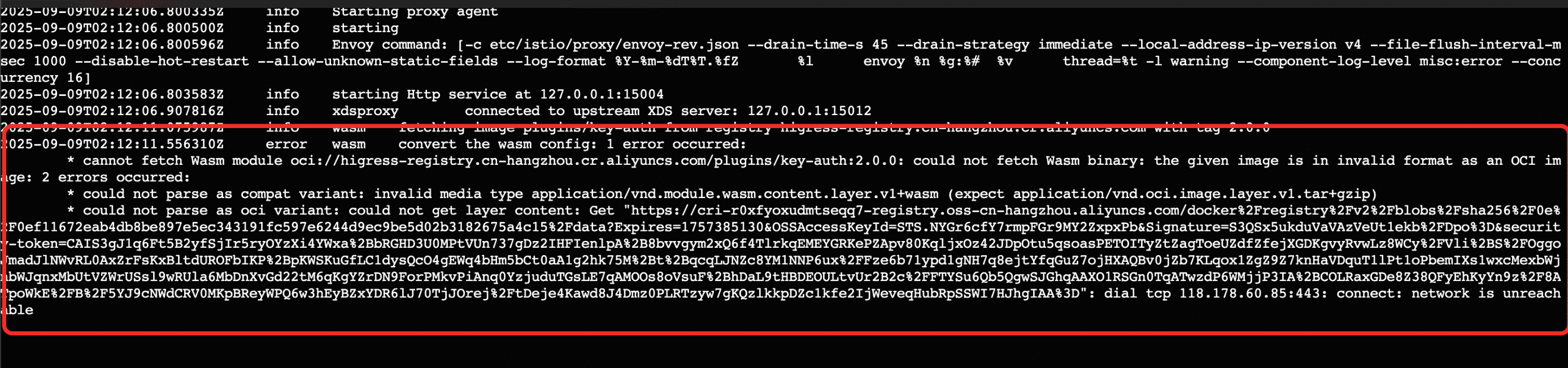
我们先尝试直接引用docker镜像进行部署时,会报wasm的插件错误,查看报错信息是通过oci地址去下载wasm插件的时候出现了问题。同时Higress实现MCP功能也依赖了wasm插件,这是一个绕不开的问题。
FROM higress-registry.cn-hangzhou.cr.aliyuncs.com/higress/all-in-one:latest
WASM插件独立部署
Higress的plugin-server项目就是为了“解决私有化部署 Higress 网关时拉取插件的痛点,优化了插件的下载与管理效率”,使Higress通过http的方式去下载独立部署的插件库,而不是通过oci去访问外部公开仓库,避免因网络问题导致插件拉取不下来。解决过程主要分为以下三个步骤:
(1)私有化部署plugin-server
FROM higress-registry.cn-hangzhou.cr.aliyuncs.com/higress/plugin-server:1.0.0
(2)为plugin-server集群申请K8s Service(Cluster IP)
apiVersion: v1
kind: Service
metadata:
name: higress-plugin-server
namespace: higress-system
labels:
app: higress-plugin-server
higress: higress-plugin-server
spec:
type: ClusterIP
ports:
- port: 80
protocol: TCP
targetPort: 8080
selector:
app: higress-plugin-server
higress: higress-plugin-serverK8s集群内置的DNS为此创建的域名解析记录的格式为<service-name>.<namespace>.svc.cluster.local。
在没有K8s的场景下也可以为plugin-server集群申请内网VIP或者SLB做好服务发现和负载均衡。
(3)修改Higress内置插件下载地址
依照github中的示例,在基于Higress镜像的项目dockerfile中声明插件的下载地址。这里有个地方需要注意下,readme中给出的示例是环境变量的格式。

在dockerfile中声明需要转义一下,\${name}/\${version}的形式才可以被正确解析。
...
# 模版
ENV HIGRESS_ADMIN_WASM_PLUGIN_CUSTOM_IMAGE_URL_PATTERN=http:
# mcp wasm 插件下载地址
ENV MCP_SERVER_WASM_IMAGE_URL=http:
...
配置完独立的插件HTTP下载地址后重新部署,在服务器上可以看到8080端口以及8443端口可以被正常监听,说明Higress具备代理和网关功能的核心数据面组件已经可以正常服务了。
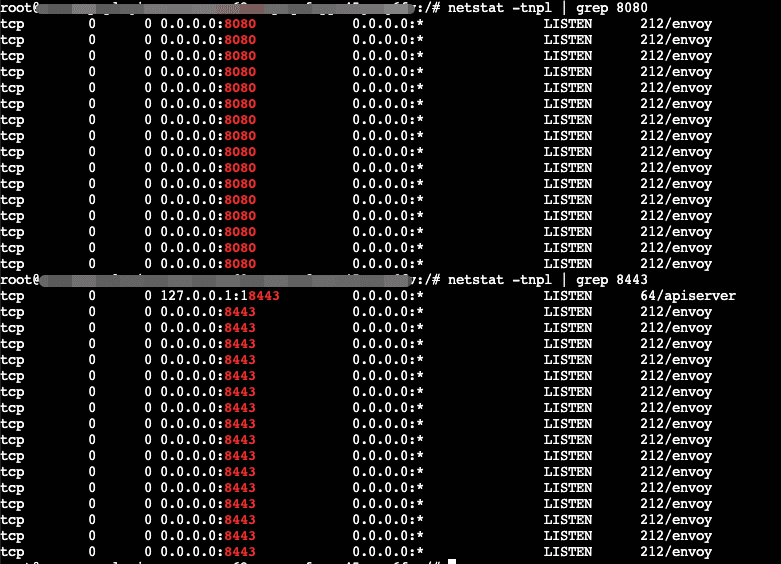
解决完wasm插件下载问题,基于docker镜像的Higress服务就可以被成功拉起并运行了。只不过基于这种模式部署的每个pod都是独立、对等、包含全部组件、功能完整的Higress服务,需要通过多副本的方式实现高可用。
这种部署模式下,通过Higress自身集成的控制台去运维服务&更改配置是不现实的,只能操作一台实例的配置变更,无法让实例间进行配置同步。因此在这种模式下的缺点是,只能通过在项目代码中维护配置文件,需要更改时走发布流程,将配置发布到每台实例上面。不过在我们这个场景下,需要变更配置的情况不多。
粘性会话
在MCP SSE通信方式下,天然需要解决粘性会话的问题,Higress基于Redis帮我们解决了这个问题。提前部署好Redis实例之后,打开Higress的MCP功能,并将Redis配置更新进去,重新部署一下就可以使用MCP的功能了。
...
data:
higress: |-
mcpServer:
enable: true
sse_path_suffix: /sse
redis:
address: xxx.redis.zhangbei.rds.aliyuncs.com:6379
username: ""
password: "xxx"
db: 0
这份配置文件可以维护在自己的基于Higress镜像的项目中,在部署的时候将配置文件COPY到指定目录(这种部署模式下,所有的配置文件都应该这么做)。
...
# custom config
COPY config/configmaps/higress-config.yaml /data/configmaps/higress-config.yaml
COPY config/mcpbridges/default.yaml /data/mcpbridges/default.yaml
COPY config/secrets/higress-console.yaml /data/secrets/higress-console.yaml
RUN chmod +x /data/configmaps/higress-config.yaml && \
chmod +x /data/secrets/higress-console.yaml && \
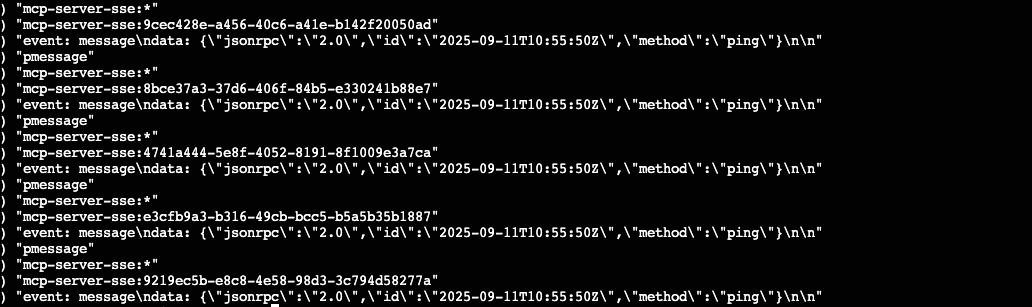
chmod +x /data/mcpbridges当整个MCP网关搭建完并使用的时候,在redis上通过 PSUBSCRIBE mcp-server-sse:* 命令可以看到如下的调用信息。
自定义构建镜像
官方构建出来的镜像一般会要求体积小,满足最小运行要求,所以很多功能其实并不集成在Higress的镜像中。如果你的企业有自己约定的通用镜像,或者是想在原本的基础上集成一些新的功能,如使用阿里云的SLS、云监控等功能,就需要根据all-in-one镜像的dockerfile内容进行自定义构建。这里有个注意的点是,Higress中的envoy模块要求的glibc是2.18及以上版本。
其实只需要将Higress的dockerfile文件内容移植过来就行,然后再声明下独立部署的WASM插件下载地址,就能实现基于指定镜像进行Higress自定义构建打包部署了。
Higress服务搭建好后,就可以走对外公网访问的流程了:(1)一个是绑定8001端口,通过Higress控制台进行查看相关配置的域名,限制为只允许内网访问。注:这种模式下无法通过控制台直接去更改配置;(2)另一个是绑定8080端口,对外提供MCP网关服务的域名。
完整的Dockerfile如下:
FROM [企业内部基础镜像]
# 下面为 Higress all-in-one dockerfile中的内容
ARG HUB=higress-registry.cn-hangzhou.cr.aliyuncs.com/higress
...
# 模版
ENV HIGRESS_ADMIN_WASM_PLUGIN_CUSTOM_IMAGE_URL_PATTERN=http:
# mcp wasm 插件下载地址
ENV MCP_SERVER_WASM_IMAGE_URL=http:
...
# 注意 dockerfile 中会去 github 下载对应处理器架构下的 yq 模块,企业内网环境下可以提前下载下来
COPY ./yq_linux_[arch] /usr/local/bin/yq
...
# custom config
COPY config/configmaps/higress-config.yaml /data/configmaps/higress-config.yaml
COPY config/mcpbridges/default.yaml /data/mcpbridges/default.yaml
COPY config/secrets/higress-console.yaml /data/secrets/higress-console.yaml
RUN chmod +x /data/configmaps/higress-config.yaml && \
chmod +x /data/secrets/higress-console.yaml && \
chmod +x /data/mcpbridgesNacos
Nacos的部署相对简单,除了通过kubectl或者nacos-operator工具直接操作K8s集群部署外,还可以直接基于nacos-server的镜像进行部署[Dockerfile]。因上文提到的内部环境问题,我们这里选择基于nacos-server的镜像,将服务部署于K8s集群上面。
FROM nacos-registry.cn-hangzhou.cr.aliyuncs.com/nacos/nacos-server:latest
集群模式部署
Nacos集群模式下使用的一致性协议是基于Raft实现的,因此最小需要部署3台实例。
在引用nacos-server镜像的dockerfile中,声明cluster的部署模式。我们查看nacos的启动脚本,发现在peer-finder(插件)目录不存在的情况下,如果定义了$NACOS_SERVERS变量,会将$NACOS_SERVERS变量中的值写入$CLUSTER_CONF文件中,$CLUSTER_CONF文件的默认路径是/home/nacos/conf/cluster.conf,其中定义的就是Nacos集群的静态成员地址列表,它在集群首次启动时会被读取,用于告知每个节点“邻居”在哪,从而让它们能够互相发现、建立连接,并初始化Raft一致性协议。
...
PLUGINS_DIR="/home/nacos/plugins/peer-finder"
function print_servers() {
if [[ ! -d "${PLUGINS_DIR}" ]]; then
echo "" >"$CLUSTER_CONF"
for server in ${NACOS_SERVERS}; do
echo "$server" >>"$CLUSTER_CONF"
done
else
bash $PLUGINS_DIR/plugin.sh
sleep 30
fi
}
...因此我们可以在dockerfile中维护当前集群下的[实例IP:端口]列表,供Nacos集群启动时读取并初始化。
...
ENV MODE=cluster
ENV NACOS_AUTH_TOKEN=xxx
ENV NACOS_AUTH_IDENTITY_KEY=xxx
ENV NACOS_AUTH_IDENTITY_VALUE=xxx
ENV NACOS_SERVERS="10.0.0.1:8848 10.0.0.2:8848 10.0.0.3:8848"
# nacos 用户名密码
ENV NACOS_USERNAME=xxx
ENV NACOS_PASSWORD=xxx
实例间动态发现
上面这种固定IP列表的方式缺点是显而易见的。它是一个静态的配置,当出现集群的扩缩容时,实例是没有办法自动去更新成员IP列表的,需要手动修改并发布,整个过程非常繁琐,严重情况下可能会影响线上服务的稳定性;且在云原生容器化背景下,IP并不是固定的,随时有可能会因为故障迁移而改变IP,维护静态IP列表与云原生的理念背道而驰。线上生产是完全不推荐这种方式的。
再回到上面docker-startup.sh脚本,可以通过peer-finder插件来实现集群间实例的发现,取代手动维护cluster.conf文件。peer-finder插件运行依赖于K8s集群Headless Service域名,会去执行类似于nslookup命令查找Service下面的所有健康Pod的IP列表,类比于服务发现的能力[脚本源码],这样就不用再手动去维护实例IP列表。
但是peer-finder的运行依赖于StatefulSet的实例部署模式,需要每个实例有固定的实例名。因为我们内部环境的限制,我们现在部署的都是无状态的实例,所以没有办法通过peer-finder来做这个事情。但是我们可以参照peer-finder脚本的实现思路,来自己写一个启动脚本。
(1)首先为Nacos集群申请Headless的Service。
apiVersion: v1
kind: Service
metadata:
name: nacos-headless
namespace: mcp-nacos
labels:
app: mcp-nacos
nacos: mcp-nacos
spec:
clusterIP: None
ports:
- name: peer-finder-port
port: 8848
protocol: TCP
targetPort: 8848
selector:
app: mcp-nacos
sessionAffinity: None
type: ClusterIP
(2)这里修改下nacos-docker的启动脚本,提供一个简单的实现(仅供参考)
...
原docker-startup.sh内容
...
# 新增内容
# 注释掉 JAVA启动命令
# exec $JAVA ${JAVA_OPT}
export JAVA_OPT # export JAVA 启动参数,方面下面读取
HEADLESS_SERVICE_FQDN="xxx.svc.cluster.local"
CLUSTER_CONF_FILE="/home/nacos/conf/cluster.conf"
UPDATE_SCRIPT="/home/nacos/bin/update-cluster.sh" # 原子更新脚本
NACOS_START_CMD="$JAVA $JAVA_OPT"
# 1. 动态创建 update-cluster.sh 脚本
cat > ${UPDATE_SCRIPT} << 'EOF'
#!/bin/bash
set -e
NACOS_PORT=${NACOS_APPLICATION_PORT:-8848}
CLUSTER_CONF_FILE="/home/nacos/conf/cluster.conf"
TMP_CONF_FILE="/home/nacos/conf/cluster.conf.tmp"
> "${TMP_CONF_FILE}"
# 从标准输入读取 nslookup 的原始输出
awk '
/^Name:/ { flag=1; next }
flag && /^Address:/ { print $2; flag=0 }
' | while IFS= read -r ip; do
if [ -n "$ip" ]; then
echo "${ip}:${NACOS_PORT}" >> "${TMP_CONF_FILE}"
fi
done
# 排序以确保文件内容的一致性,避免不必要的更新
sort -o "${TMP_CONF_FILE}" "${TMP_CONF_FILE}"
# 只有在新旧配置不同时才执行更新
# 检查旧文件是否存在
if [ ! -f "${CLUSTER_CONF_FILE}" ] || ! cmp -s "${TMP_CONF_FILE}" "${CLUSTER_CONF_FILE}"; then
echo "[$(date)][update-script] Peer list changed. Updating config."
mv "${TMP_CONF_FILE}" "${CLUSTER_CONF_FILE}"
echo "[$(date)][update-script] cluster.conf updated:"
cat "${CLUSTER_CONF_FILE}"
else
rm "${TMP_CONF_FILE}"
fi
EOF
chmod +x ${UPDATE_SCRIPT}
# 2. 启动前的初始化循环
MAX_INIT_RETRIES=30
RETRY_COUNT=0
MIN_PEERS=3 # 期望的集群最小副本数量
echo "[INFO] Initializing cluster config. Waiting for at least ${MIN_PEERS} peers to be available..."
while true; do
# 直接将 nslookup 的输出通过管道传给更新脚本
nslookup "${HEADLESS_SERVICE_FQDN}" | ${UPDATE_SCRIPT}
# 检查生成的配置文件行数
LINE_COUNT=$(wc -l < "${CLUSTER_CONF_FILE}")
if [ "${LINE_COUNT}" -ge "${MIN_PEERS}" ]; then
echo "[INFO] Initial cluster.conf is ready with ${LINE_COUNT} peers."
break
fi
RETRY_COUNT=$((RETRY_COUNT+1))
if [ "${RETRY_COUNT}" -gt "${MAX_INIT_RETRIES}" ]; then
echo "[WARN] Could not find ${MIN_PEERS} peers after ${MAX_INIT_RETRIES} retries. Starting with ${LINE_COUNT} peers found."
break
fi
echo "[INFO] Found ${LINE_COUNT} peers. Waiting for more... Retrying in 5 seconds."
sleep 5
done
# 3. 在后台启动我们自己的监控循环
(
while true; do
sleep 15 # 每 15 秒检查一次
echo "[$(date)][monitor] Checking for peer updates..."
nslookup "${HEADLESS_SERVICE_FQDN}" | ${UPDATE_SCRIPT}
done
) &
# 4. 启动 Nacos 主进程
echo "[INFO] Starting Nacos server..."
exec sh -c "${NACOS_START_CMD}
这样我们cluster.conf文件中的成员IP列表就实现了自动更新。
线上生产环境还是推荐使用有状态StatefulSet的部署模式,并结合peer-finder的能力实现实例间的互相发现。而不是用无状态的实例,自己去写脚本实现。后续我们也会升级到StatefulSet的模式进行部署。
配置外置Mysql
在集群部署模式下,就无法使用Nacos内置的不支持数据共享的Derby数据库,需要配置外置的Mysql数据库。提前部署好Mysql实例之后,按照nacos中的mysql-schema.sql数据库配置文件将表初始化,再将mysql配置信息写入dockerfile中即可。
...
# mysql config
ENV SPRING_DATASOURCE_PLATFORM=mysql
ENV MYSQL_DATABASE_NUM=1
ENV MYSQL_SERVICE_HOST=xxx.mysql.zhangbei.rds.aliyuncs.com
ENV MYSQL_SERVICE_PORT=3306
ENV MYSQL_SERVICE_DB_NAME=nacos
ENV MYSQL_SERVICE_USER=xxx
ENV MYSQL_SERVICE_PASSWORD=xxx
在为Nacos做服务暴露的时候,只需要暴露nacos控制台的8080端口,且限制为只允许内网访问即可。因为nacos只是内部作为维护管理MCP工具元数据信息的MCP Registry使用,对用户侧不感知;且Higress和Nacos都部署在内网的K8s集群上面,内部通信通过K8s的Service即可,无需将Nacos的8848端口暴露给公网。
申请K8s Service供Higress使用
注意Higress拉取/订阅Nacos中的配置会通过gRPC的方式调用,这里的Service需要暴露8848和9848两个端口给Higress使用。
apiVersion: v1
kind: Service
metadata:
name: pre-oss-mcp-nacos-endpoint
namespace: aso-oss-mcp-nacos
labels:
app: mcp-nacos
nacos: mcp-nacos
spec:
type: ClusterIP
ports:
- name: subscribe-port
port: 8848
protocol: TCP
targetPort: 8848
- name: grpc-port
port: 9848
protocol: TCP
targetPort: 9848
selector:
app: nacos同理,如果想使用企业内部的镜像,或者是想在原本的基础上即成一些新的功能,如使用阿里云的SLS、云监控等功能,也可根据Nacos的dockerfile进行自定义构建部署。
鉴权
Higress自身提供了丰富的鉴权能力,如果你的企业本身就基于Higress搭建了自己的网关并使用了Higress提供的鉴权能力,这种场景下直接复用原来的方案即可。
另一种场景下,企业中会有多个服务Provider,每个Provider有不同的鉴权方式。如下图所示,某个服务提供者会通过拦截器对请求中携带的用户Cookie进行RAM鉴权;另一个服务提供者会通过tengine lua脚本对请求进行自定义鉴权;以及后续注册的服务可能有其他的鉴权方式。

一方面,我们并不希望使用Higress的鉴权能力去覆盖全部的鉴权场景,开发维护成本过高,我们优先考虑直接复用服务提供者已有的鉴权能力;另一方面,如果通过网关层鉴权需要将AK或者认证信息存放在Higress服务上,在安全层面也不是一个合适的做法。
这里推荐的做法是直接在MCP工具调用的时候,将鉴权信息透传给服务提供者,让服务提供者完成鉴权。
MCP验证
https://www.nacos.io/blog/nacos-gvr7dx_awbbpb_lup4w7e1cv6wktac/#_top
根据文档中的操作示例,我们可以简单做个全链路测试验证。主要分为以下三步:
(1)在nacos中注册服务,并配置MCP工具的元数据信息:
在public命名空间下,创建服务信息
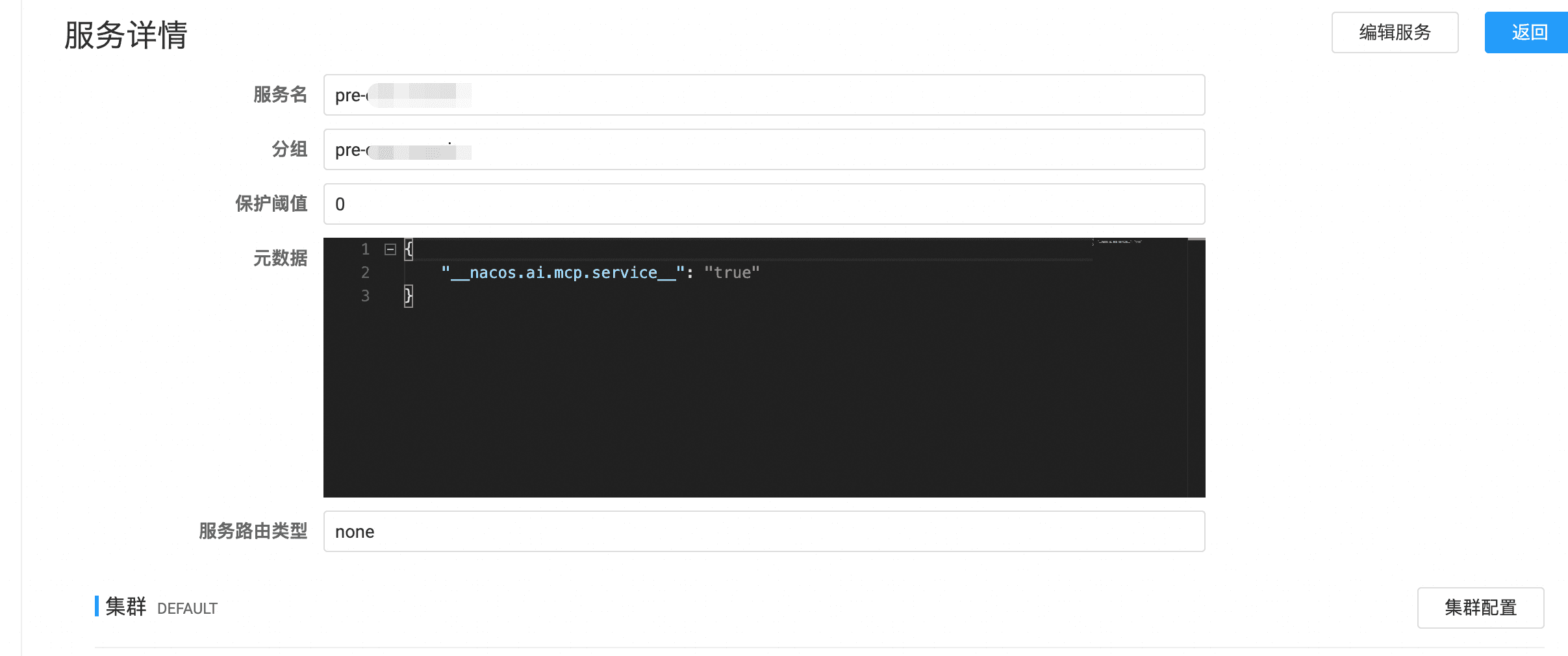
在机器上将自己的服务作为永久实例注册进去(这里为了快速验证黑屏登陆机器操作,线上生产环境还是须要白屏操作)
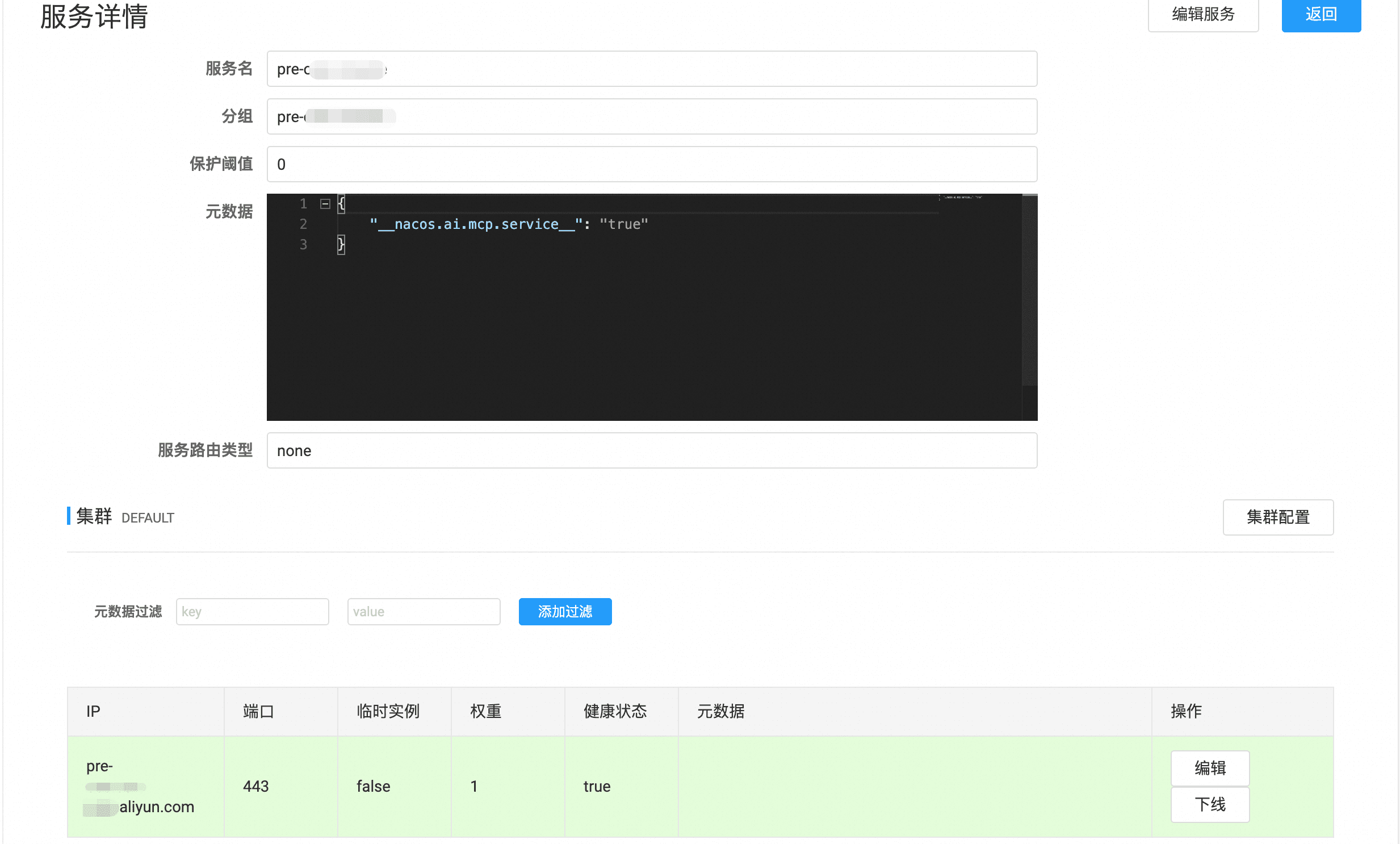
curl -X POST 'http://127.0.0.1:8848/nacos/v1/ns/instance?namespaceId=[namespace]&serviceName=[service_name]&groupName=[group_name]&ip=[服务域名]&port=[服务端口]&ephemeral=false'
注册完之后,就能在nacos控制台上看到注册的服务配置以及健康状态。
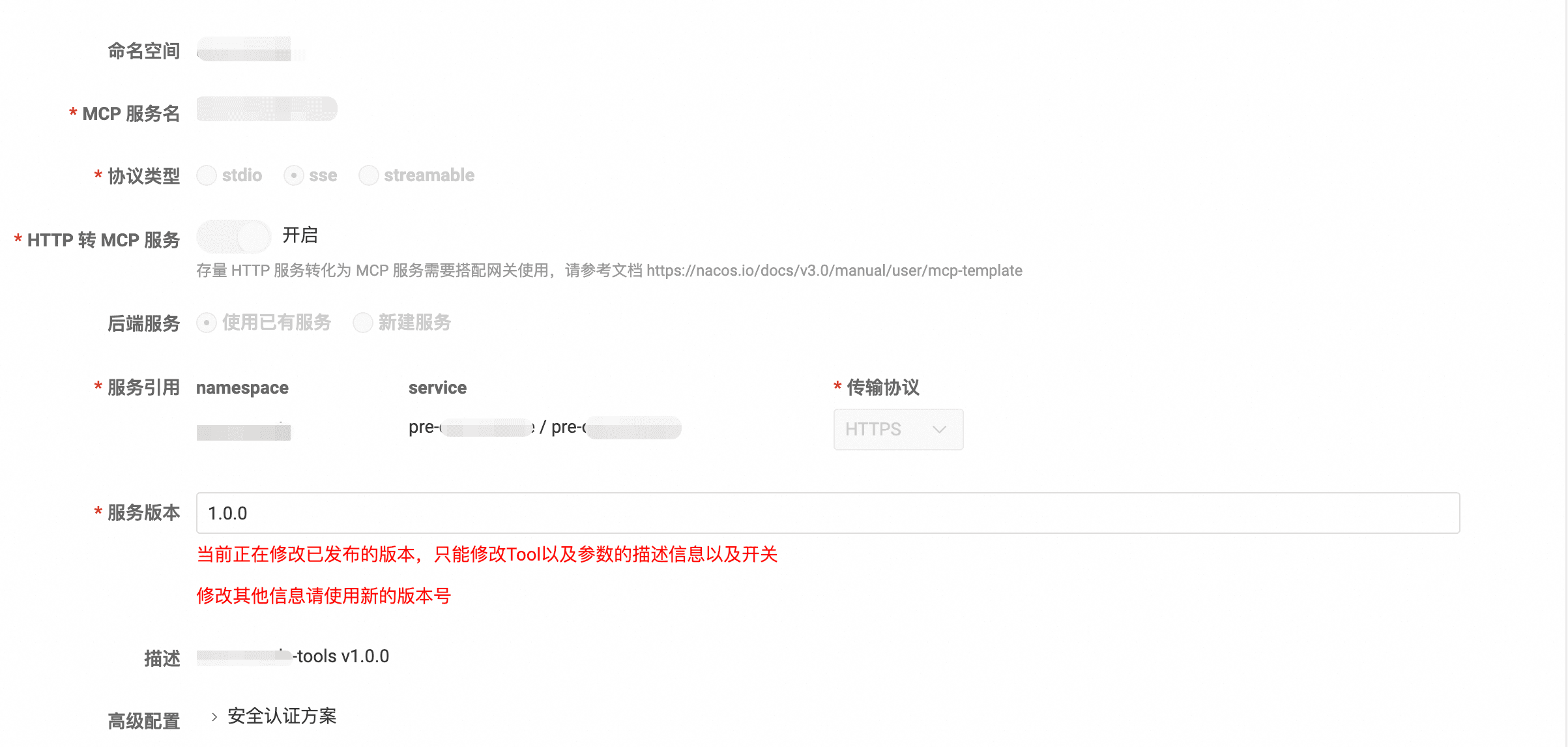
接着在nacos控制台上配置MCP工具,添加一个简单工具,可以选择一个无参数GET接口,并发布。
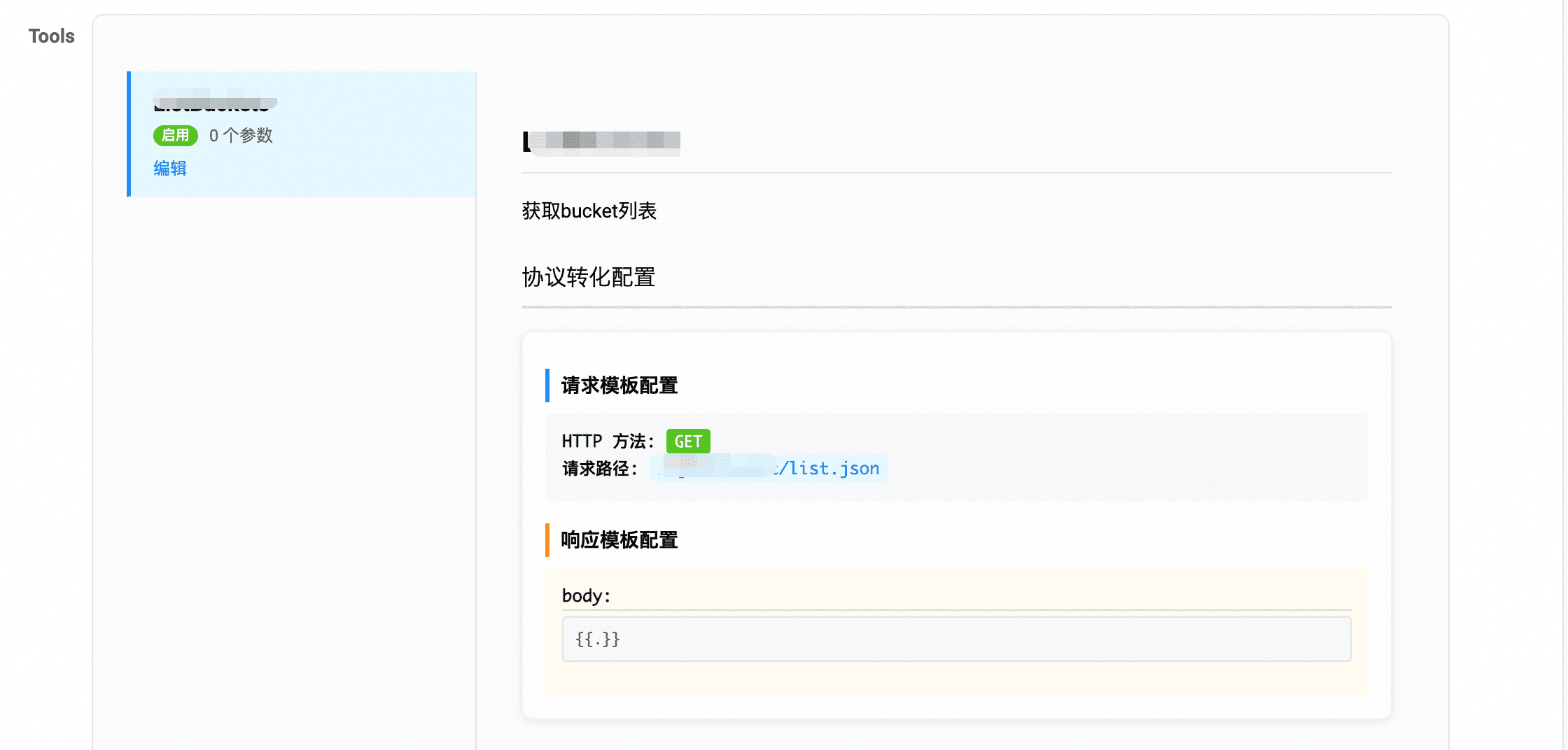
{
"requestTemplate": {
"url": "/xxx/list.json",
"method": "GET",
"headers": [],
"argsToUrlParam": true
},
"responseTemplate": {
"body": "{{.}}"
}
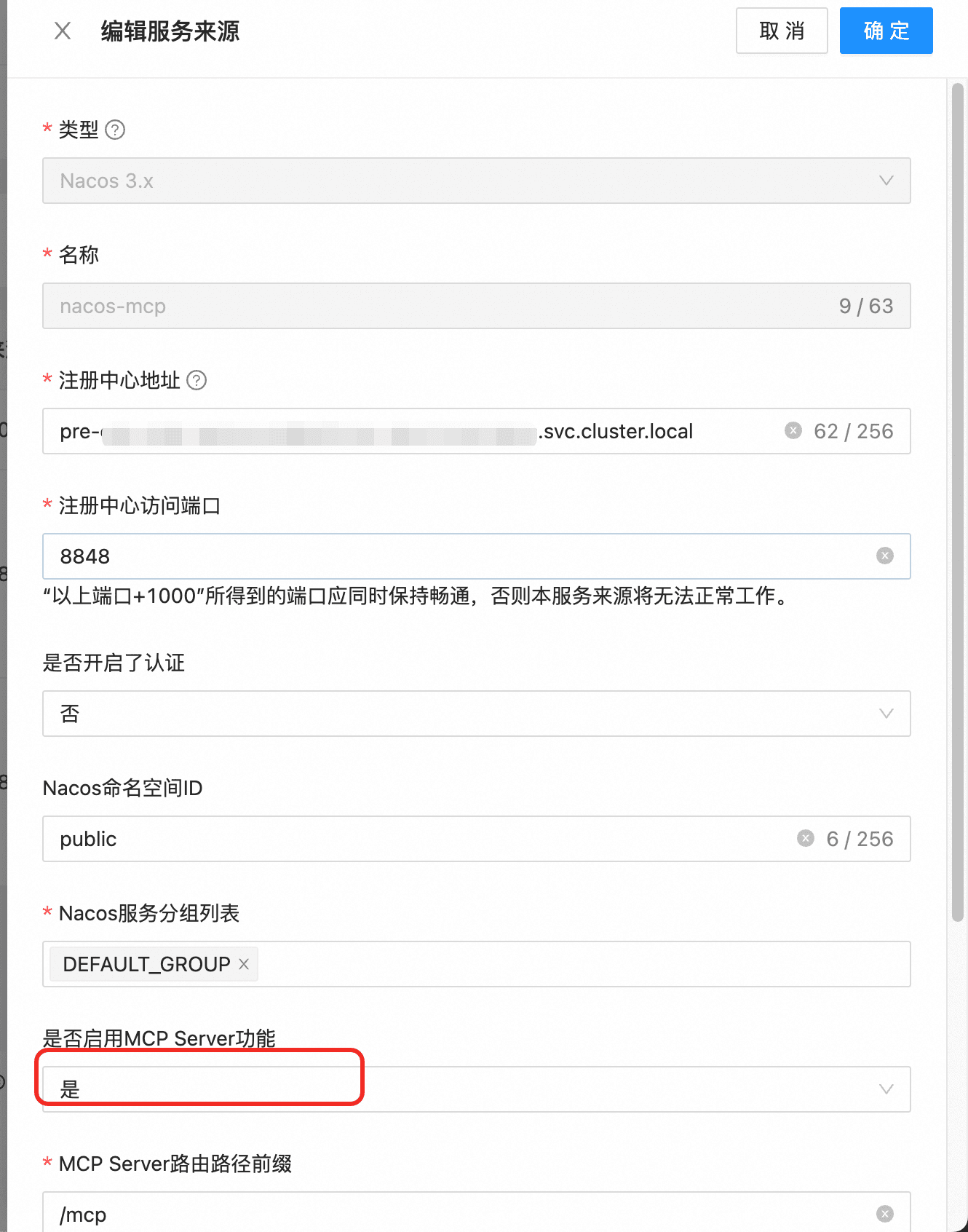
}(2)在Higress中配置MCP Nacos的服务来源:
这里为了快速测试关闭了nacos的认证,线上环境建议开启nacos的认证。
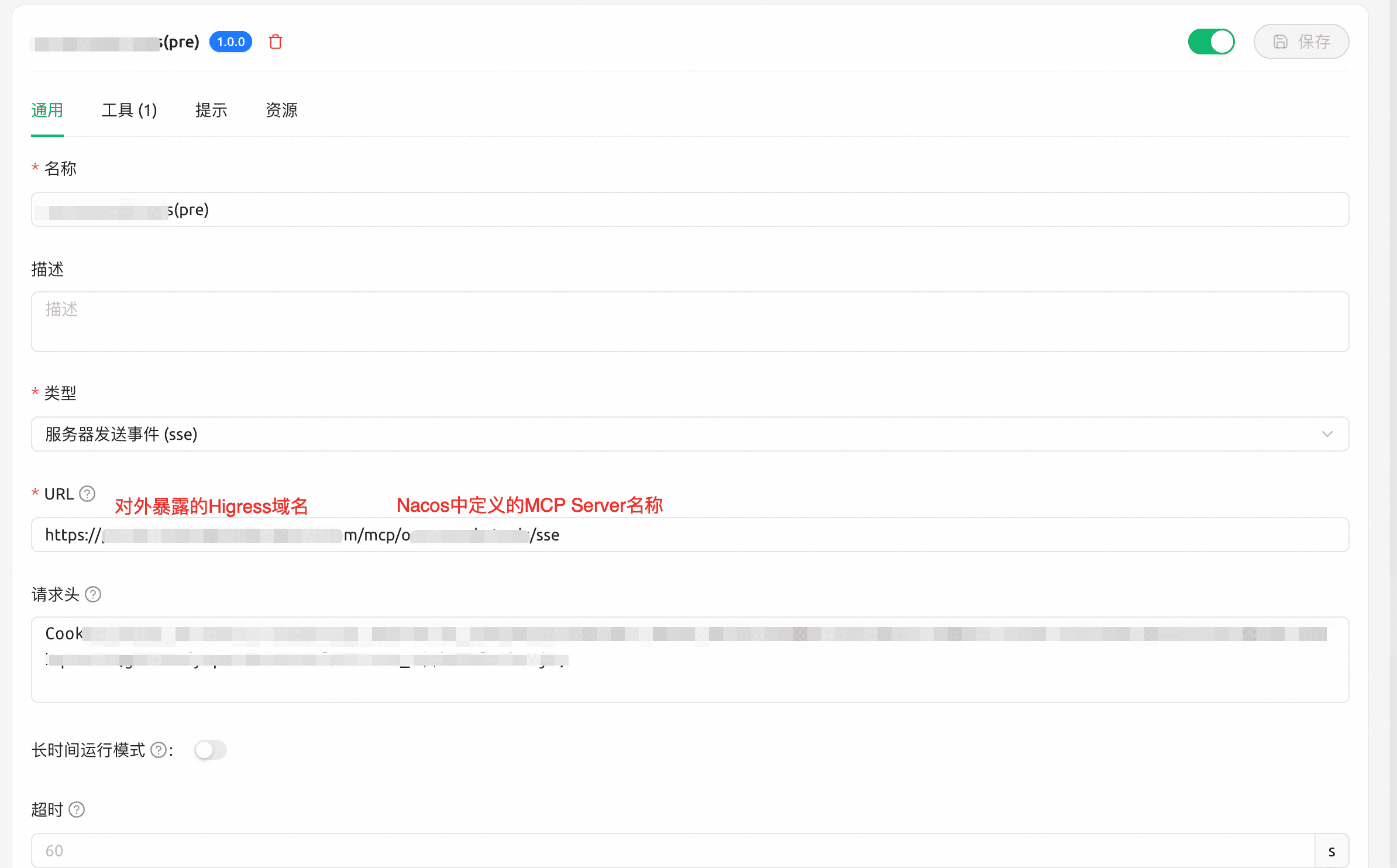
(3)在Cursor/Cherry Studio中配置对外暴露的Higress服务地址和uri,即可使用MCP工具:
设计图
容灾架构

在整个MCP网关中,通过uri来路由不同的MCP工具,实现工具的隔离。
逻辑模块图

时序图

附录
[1]修改内置插件的镜像地址
[2]higress-plugin-server
[3]Nacos 3.0 正式发布:MCP Registry、安全零信任、链接更多生态
[4]手把手带你玩转基于 Nacos + Higress 的 MCP 开发新范式
[5]Nacos集群模式





