


The assessment engineering is becoming a key focus of the next round of Agent evolution
Wang Chen & Ma YunLei
|
Oct 29, 2025
|
The CIO of Alibaba Cloud, Jiang Linquan, once shared that during the process of implementing large model technology, he summarized a set of methodologies called RIDE, which stands for Reorganize (reorganize the organization and production relations), Identify (identify business pain points and AI opportunities), Define (define metrics and operational systems), and Execute (promote data construction and engineering implementation). Among them, Execute mentioned the core reason for assessing the importance of systems, which is that the most critical distinction of this round of large models is that there are no standard paradigms for measuring data and evaluation. This means that it is both a difficulty in enhancing product capability and a moat for product competitiveness.
In the field of AI, there is often a term referred to as "taste"; here, the "taste" mentioned actually refers to how to design evaluation projects and evaluate the output of agents.
1. From Determinacy to Uncertainty
In traditional software development, testing is an indispensable part of the development process, ensuring the determinacy of inputs and outputs, as well as forward compatibility, which is the basis for software quality assurance. Test coverage and accuracy are the metrics for evaluating quality, and accuracy must be maintained at 100% level.
Traditional software is largely deterministic. Given the same inputs, the system will always produce the same outputs. Its failure modes, that is, "bugs," are usually discrete, reproducible, and can be fixed by modifying specific lines of code.
AI applications, in essence, exhibit non-deterministic and probabilistic behavior. They display statistical, context-dependent failure modes and unpredictable emergent behaviors, meaning that for the same inputs, they may produce different outputs.
The traditional QA process, designed specifically for predictable, rule-based systems, has been unable to adequately address the challenges posed by these data-driven, adaptive systems. Even with thorough testing during the release phase, it cannot guarantee stability issues after going live with various outputs. Therefore, evaluation is no longer just a phase before deployment, but rather a combination of observability platforms, continuous monitoring, and automated evaluation and governance as a service that constitutes the evaluation project.
2. The Root Causes of Uncertainty
The non-determinacy of AI applications stems from their core technological architecture and training methods. Unlike traditional software, AI applications are in essence probabilistic systems. Their core function is to predict the next word in a sequence based on statistical patterns learned from massive data rather than true understanding. This inherent randomness is both the source of their creativity and the root of their unreliability, leading to the phenomenon of "hallucination," where the model generates outputs that sound reasonable but are actually incorrect or nonsensical.
The root causes of hallucination and uncertainty are complex:
Defects caused by data: The knowledge of the model is entirely limited to its training data. If the data is incomplete, contains factual errors, or reflects social biases, the model will inherit and amplify these defects. It cannot provide information outside of the training data, such as future events or private data it has never encountered.
Products of architecture and modeling: The Transformer architecture and its training process introduce uncertainty. The core task of predicting the next token encourages the model to make "guesses" when information is insufficient. Overfitting to training data can lead the model to memorize rather than generalize, and mistakes in attention mechanisms may cause it to overlook key parts of prompts.
Misalignment and uncertainty: The model may possess accurate knowledge, but due to not being fully aligned with the user's specific instructions, it fails to apply that knowledge correctly. While hallucinations are often associated with the model's uncertainty, research shows that models can also hallucinate with high confidence, making such errors particularly subtle and difficult to detect.
3. Defeating Magic with Magic
Traditional automated evaluation metrics, such as BLEU (Bilingual Evaluation Understudy) for machine translation and ROUGE (Recall-Oriented Understudy for Gisting Evaluation) for text summarization, are primarily based on the overlap of vocabulary or phrases to calculate scores. This approach fundamentally falls short when evaluating modern generative AI models, which need to capture subtle differences in semantics, style, tone, and creativity. A model-generated text might be completely different from the reference answer in wording but could be more accurate and insightful semantically. Traditional metrics fail to recognize this, and may even assign low scores.
On the other hand, while human evaluation is regarded as the "gold standard" for assessment quality, its high costs, lengthy cycles, and inherent subjectivity make it difficult to adapt to the rapid iterations of AI technology development. This lag in evaluation capabilities forms a serious bottleneck, often causing promising AI projects to fall into pilot traps, unable to effectively validate and improve.
Therefore, "defeating magic with magic" has become a new paradigm in evaluation engineering, namely LLM-as-a-Judge automated evaluation tools. It utilizes a powerful large language model (usually a cutting-edge model) to act as a judge, scoring, ranking, or selecting the outputs of another AI model (or application). This approach cleverly combines the scalability of automated evaluation with the meticulousness of human evaluation.
4. Open Source Practices of Automated Evaluation Tools
In RL/RLHF scenarios, reward models (Reward Model, RM) have become a mainstream automated evaluation tool, along with benchmarks specifically for evaluating reward models, such as overseas RewardBench[1] and RM Bench[2] released jointly by domestic universities, which are used to measure the effectiveness of different RMs and compare who can better predict human preferences. Below, I will introduce ModelScope's recently open-sourced reward model — RM-Gallery, project address:
https://github.com/modelscope/RM-Gallery/
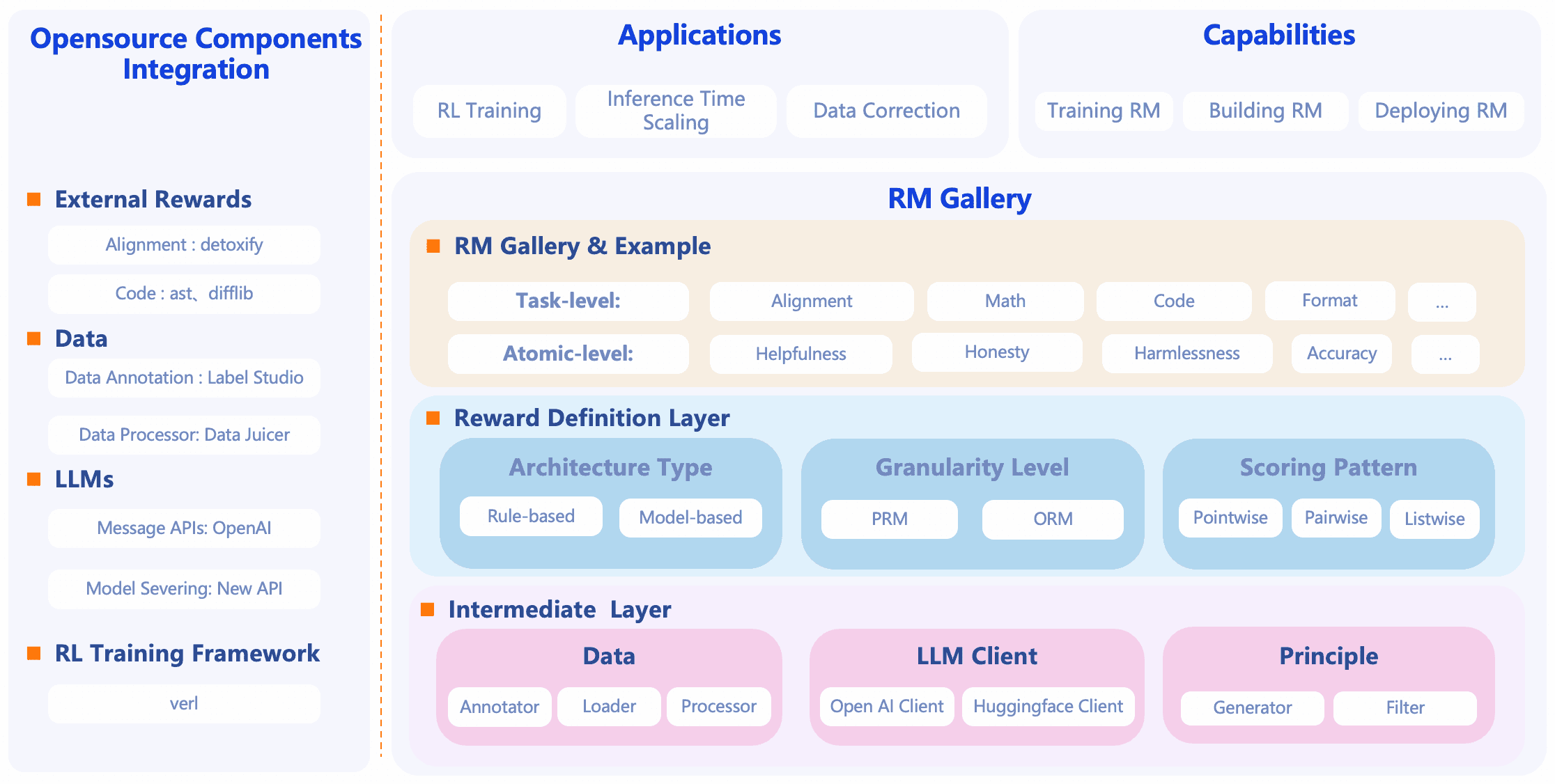
RM-Gallery is a one-stop platform that integrates reward model training, construction, and application, supporting high throughput and fault tolerance implementations for task-level and atomic-level reward models, facilitating the end-to-end realization of reward models.
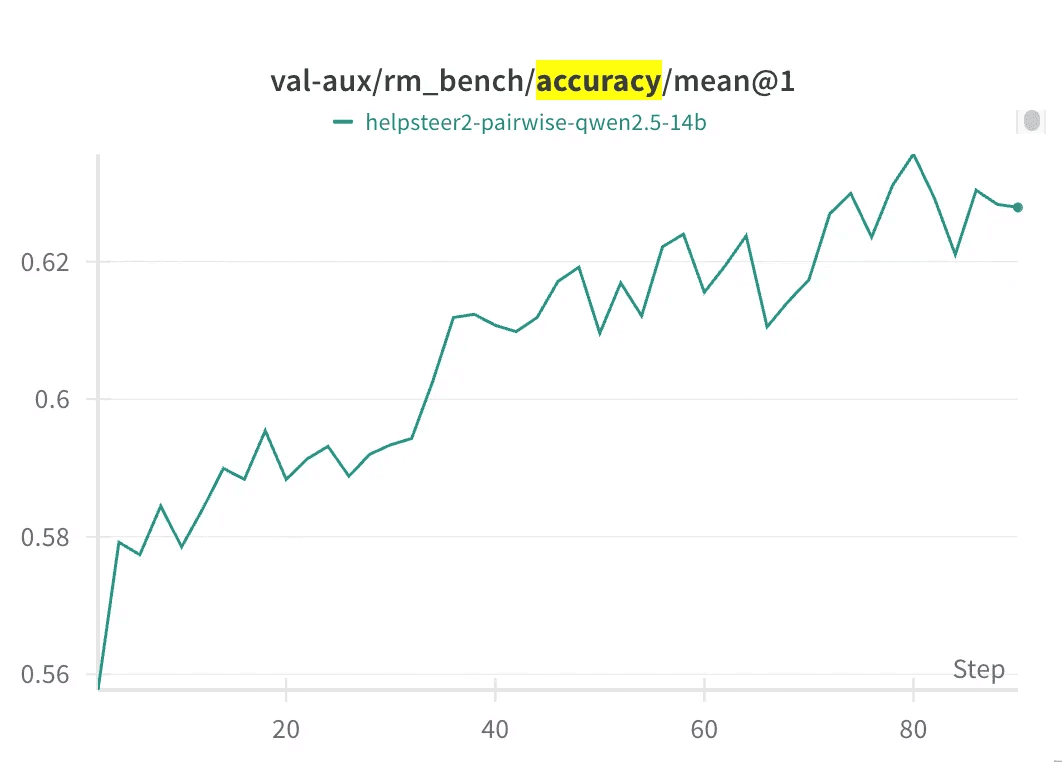
RM-Gallery provides an RL-based inference reward model training framework, compatible with mainstream frameworks (such as Verl), and offers examples for integrating RM-Gallery. In RM Bench, after 80 steps of training, accuracy improved from about 55.8% of the baseline model (Qwen2.5-14B) to about 62.5%.
Several key features of RM-Gallery include:
Support for task-level and finer-grained atomic-level reward models.
Standardized interfaces and a rich built-in model library (e.g., mathematical correctness, code quality, alignment, safety, etc.) for direct use or customization.
Support for training processes (using preference data, contrastive loss, RL mechanisms, etc.) to improve the performance of reward models.
Support applying these reward models to multiple application scenarios: such as “Best-of-N selection,” “data correction,” “post-training/RLHF” scenarios.
Thus, from a functional perspective, it is to build the reward model — used to assess the quality, priority, and preference consistency of large model outputs — into a trainable, reusable, and deployable infrastructure platform for evaluation engineering.
Of course, building a complete evaluation project requires more than a reward model; continuous collection of business data, including user dialogues, feedback, and calling logs, is needed to further optimize datasets, train smaller models, or even teacher models, forming a data flywheel.



