


Why does Alibaba Cloud want to open source the data collection development kit?
Wang Chen
|
Jan 16, 2026
|
1. Data collection is becoming the core infrastructure that determines the quality of Agents
With the continuous evolution of Agents and the ongoing prosperity of supply chains, data collection is evolving from traditional operational tools into the core infrastructure that determines the quality of Agents. Why is this the case? Below, we will analyze from three dimensions: the availability of Agent services, the reliability of Agent outputs, and the cost of Agents.
Availability of Agent services
A typical Agent application is far more complex than traditional applications.
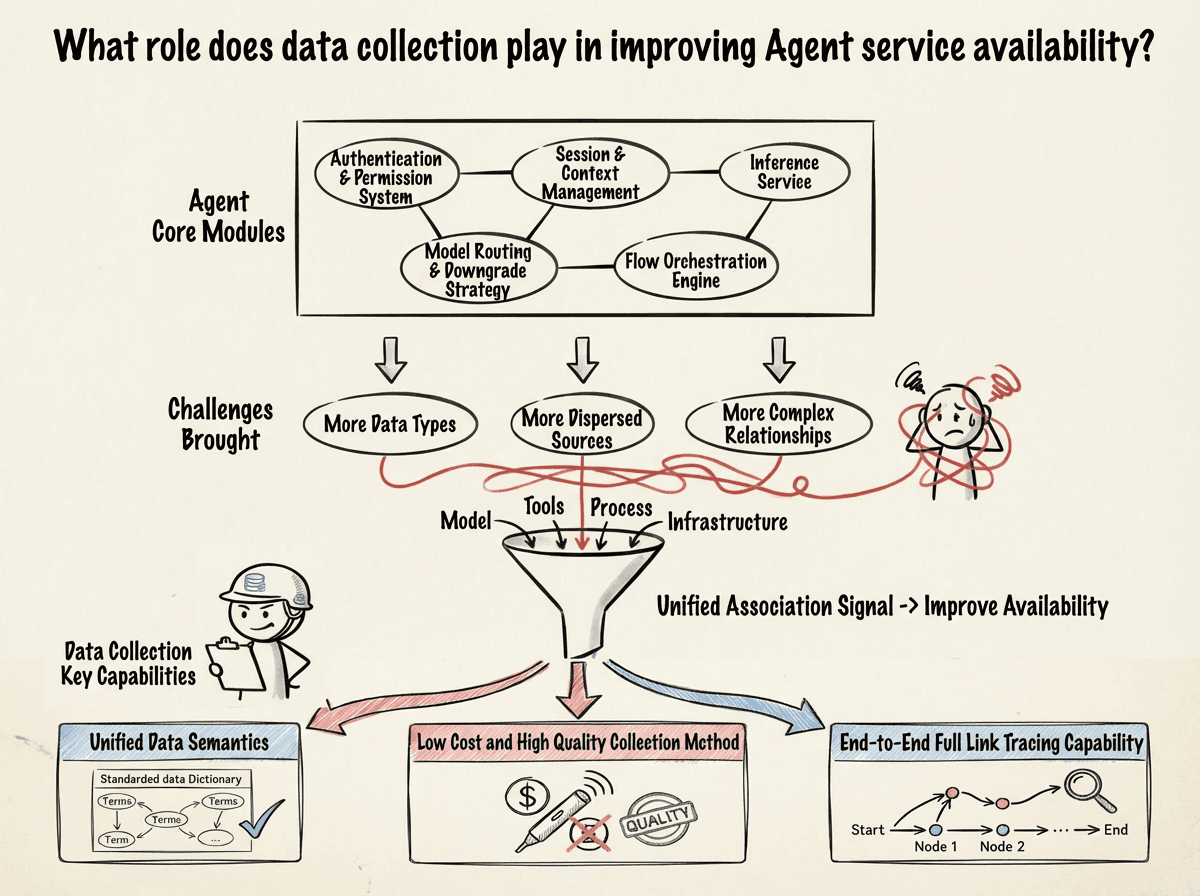
Beyond the user terminal, Agents often include core modules such as authentication and permission systems, session and context management, inference services, large model routing and degradation strategies, process orchestration engines, and more. At the same time, model inference itself heavily relies on the external world: it may call multiple model services, execute real operations through tools, maintain long-term memory through vector databases, and control the costs of LLM's repeated calls through caching mechanisms.
These components together form a highly dynamic execution chain that spans systems and semantics. With more data types, more dispersed sources, and more complex relationships, this is no longer a form of application that can be analogized to traditional software.
In this context, isolated data has almost no value.
Only by unifying the signals generated by models, tools, processes, and infrastructure can we truly answer: what exactly went wrong with the system? This requires data collection to have three capabilities: unified data semantics, low-cost and high-quality collection methods, and end-to-end full-link tracking capabilities.
Reliability of Agent outputs
The fundamental difference between Agents and traditional software lies in their autonomous decision-making characteristics.
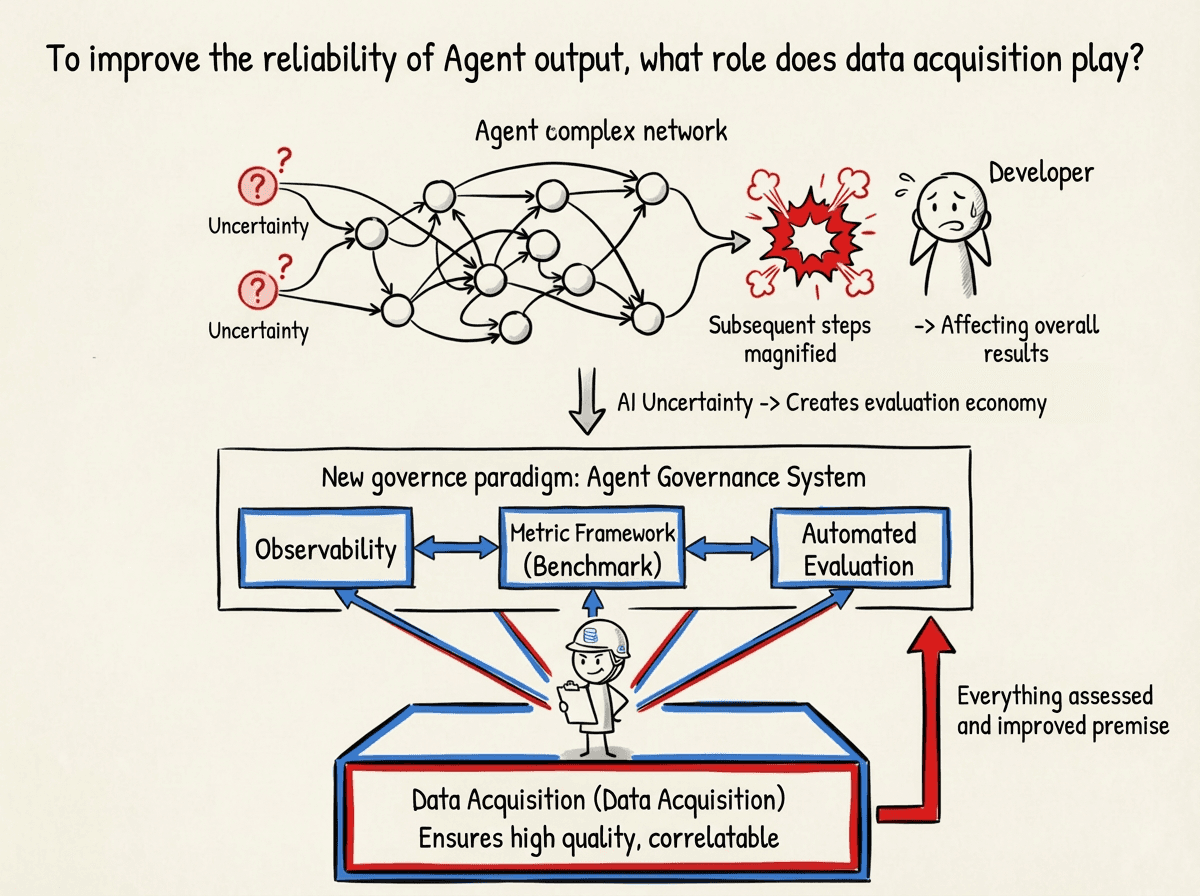
It involves multi-modal input, large model inference, tool invocation, and state feedback across multiple layers of interaction, essentially constituting a nonlinear workflow. When this workflow is投入 into a real business scenario, any uncertainty at one node will be continually amplified by subsequent steps, ultimately affecting the overall result.
Therefore, the non-determinism of AI, or the lack of standard answers, gives rise to evaluation economics.
Evaluations have evolved from being phase-based to becoming a continuous engineering practice. Assessments no longer occur after the system goes live but are carried out in parallel with the development process. Behind this gradually forms a new governance paradigm: the Agent governance system composed of observability (including data collection), measurement frameworks (Benchmark), and automated evaluations. Within this system, high-quality, correlatable data is the premise of all assessments and improvements.
Cost Control
When Agents interact with models multiple times, Token consumption often grows exponentially. In some complex scenarios, the system may even fall into an endless inference loop, forming a typical "Token black hole."
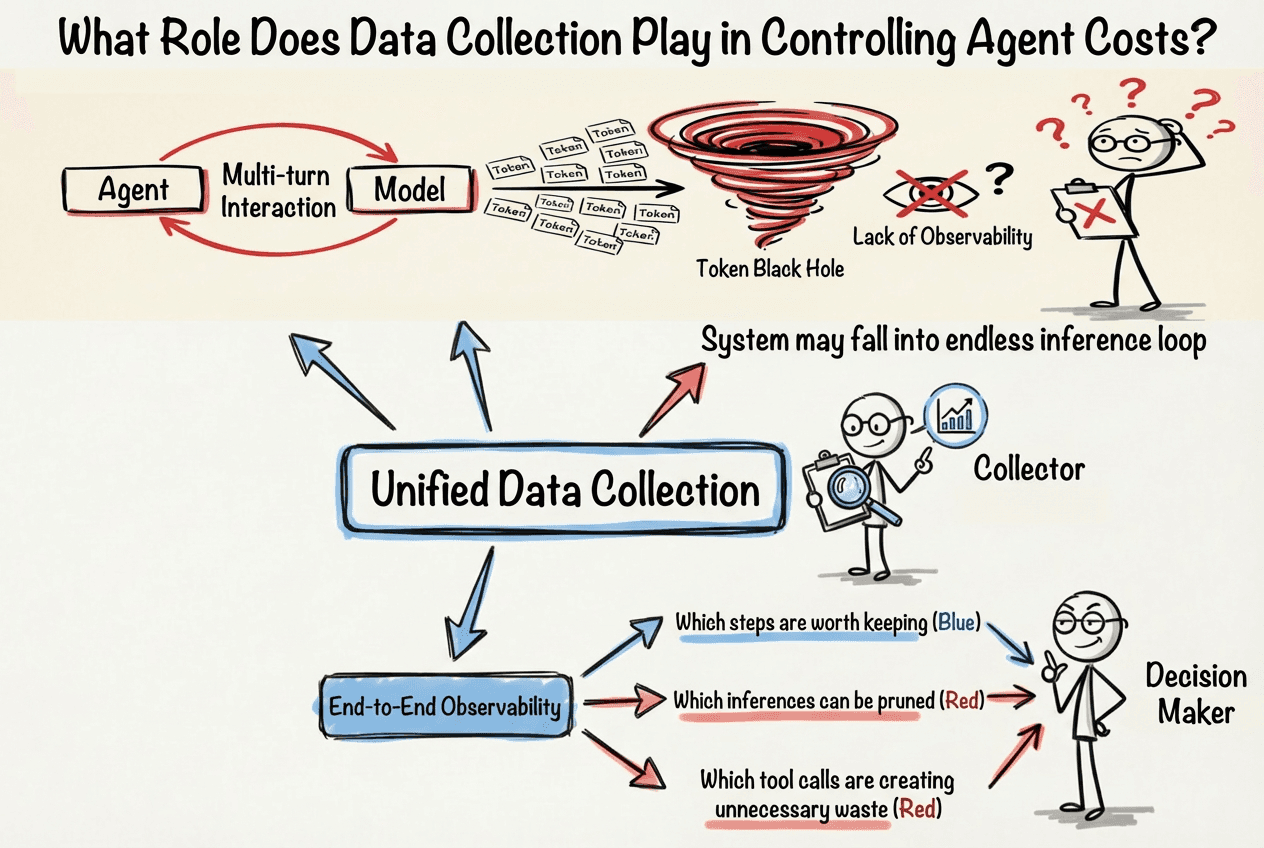
If there is a lack of link-level observability, developers cannot determine where the consumption occurs, nor can they evaluate the real benefits of optimization. Ultimately, cost control of the system can only rely on experience and guesswork. However, once end-to-end observability is established, decisions become grounded: which steps are worth keeping, which inferences can be trimmed, and which tool invocations are incurring unnecessary consumption.
Unified data collection is a prerequisite for establishing end-to-end observability.
It is against this technological backdrop that Alibaba Cloud has chosen to open source the LoongSuite data collection development kit, hoping to help more enterprises build standardized, sustainably evolving observability systems with lower costs and higher efficiency while keeping pace with the trends in AI engineering evolution.
2. Composition of LoongSuite
As an open-source data collection development kit, LoongSuite (/lʊŋ swiːt/, transliterated as 龙-sweet) consists of three parts: host probes, process-level probes, and data collection engines, among which:
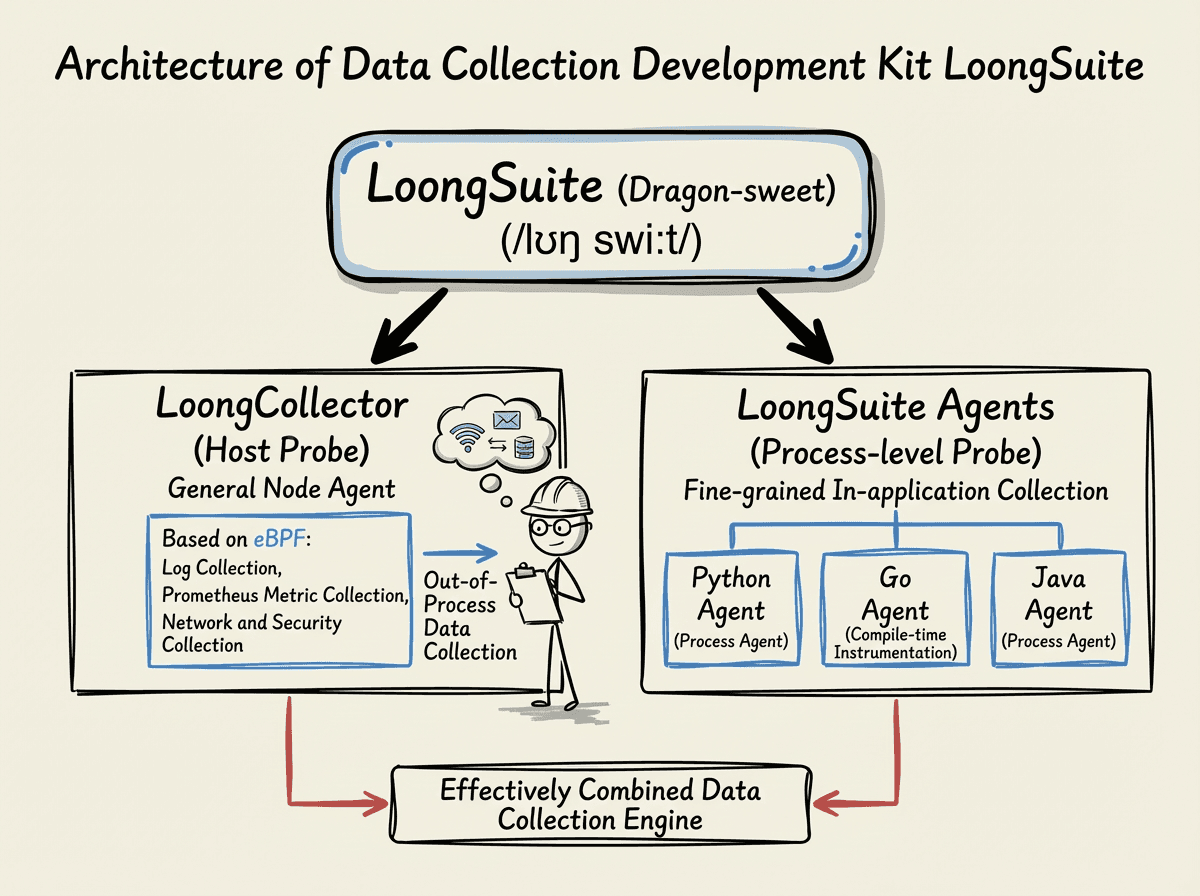
LoongCollector:
is the host probe that, based on eBPF, provides log collection, Prometheus metric collection, and network and security collection functionalities. It achieves efficient and flexible data processing and collects out-of-process data through technologies such as eBPF. At the same time, it effectively combines host-level probes with process-level instrumentation as a data collection engine.
LoongSuite multi-language Agent
is the process-level probe that collects fine-grained observable data within applications. It currently offers Agents for mainstream programming languages such as Java, Go (compile-time instrumentation), and Python, automatically capturing the function call links, parameter passing paths, and resource consumption within processes without requiring modifications to business code, enabling precise runtime state collection.
This non-intrusive design is particularly suited to technology environments with frequent dynamic updates, ensuring the integrity of observable data while avoiding interference with core business logic. When faced with complex workflows, the system can automatically associate the distributed tracing context, constructing a complete execution path topology.
Core data collection engine
In addition to the capabilities of the host probe, LoongCollector, as a core data collection engine, also implements unified handling of multidimensional observable data, from raw data collection to structured transformation, to intelligent routing and distribution, with the entire process achieved through a modular architecture for flexible orchestration. This architecture allows observable data to integrate with open-source analysis platforms for self-governance and seamlessly connect with managed services to build a cloud-native observability system.
3. What are the features of LoongSuite?
From the perspective of engineering implementation, the design goal of LoongSuite is very clear: to collect everything that should be collected and minimize costs that should not be incurred, without interfering with the business.
Zero-intrusive collection: Capturing full-link data without modifying code through the combination of process-level instrumentation and host-level probes.
Full-stack support: Covering mainstream languages such as Java, Go, and Python, adapting to the vast majority of current AI application forms.
Ecological compatibility: LoongSuite is a distribution of OpenTelemetry, deeply compatible with OT, adhering to community GenAI semantic standards, and synchronizing based on upstream; additionally, we serve as an incubator for innovation features in AI scenarios and will continuously contribute new features to the OTel community. For example, we have already donated the Go probe to the community.
On this basis, LoongCollector within LoongSuite further provides three key capabilities.
Unified collection capability for multidimensional data
In the Agent scenario, a single perspective can no longer explain system behavior.
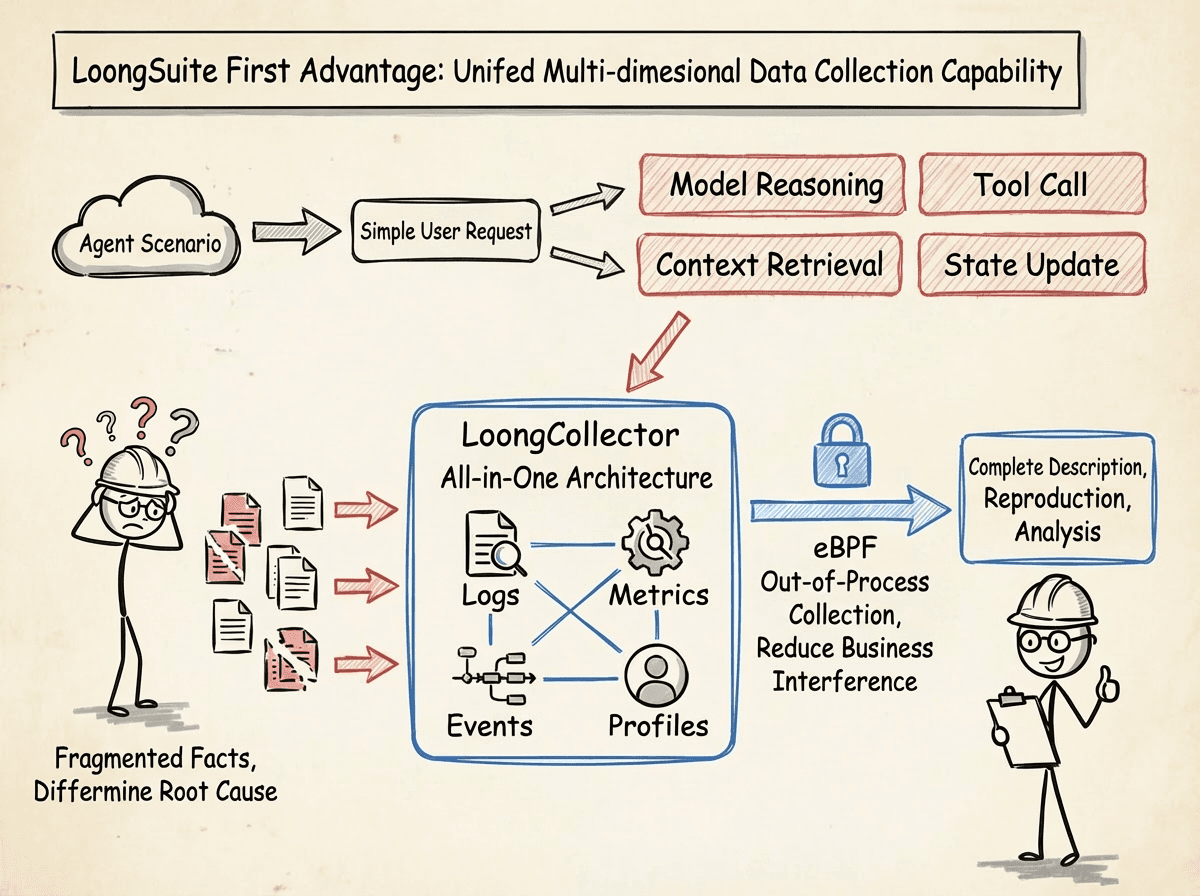
An apparently simple user request often involves multiple steps, including model inference, tool invocation, context retrieval, and state updates. Logs can only answer "what happened," metrics can only reflect "whether the overall situation is abnormal," while Traces can only show the "call sequence." If these signals are disconnected from each other, engineers will always face fragmented facts, making it impossible to determine the root cause of the problem or assess whether an optimization has truly taken effect.
LoongCollector unifies Logs, Metrics, Traces, Events, and Profiles into the same collection and correlation system, essentially restoring the true execution process of Agents, allowing problems to be fully described, reproduced, and analyzed instead of remaining at the level of "something feels wrong." LoongCollector adopts an All-in-One architecture, supporting data collection of all types, including Logs, Metrics, Traces, Events, and Profiles, while also achieving out-of-process collection through eBPF, reducing business interference.
Ultimate performance and stability
Ultimate performance and stability are uncompromising prerequisites for the data collection layer.
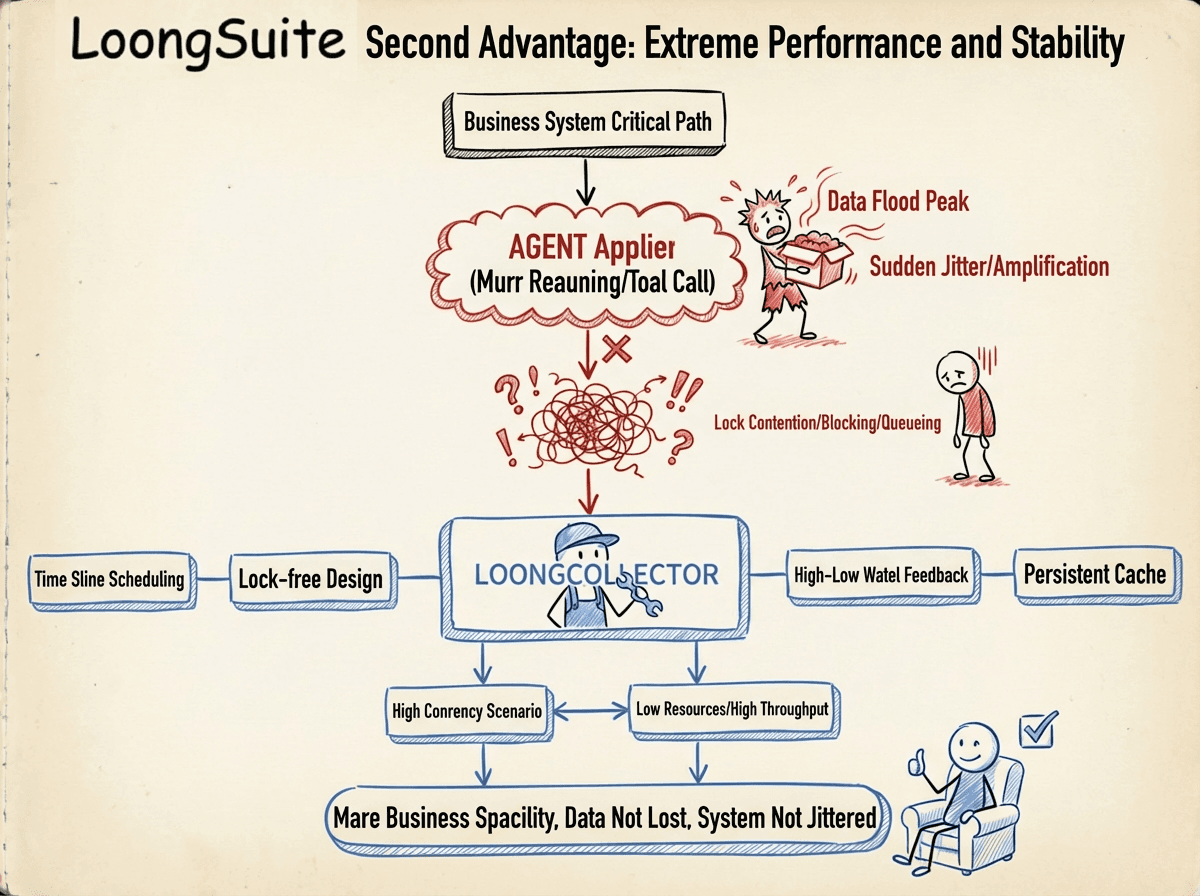
The collection system is located in the critical path of the business system, and any additional jitters introduced will be rapidly amplified. Especially in Agent applications, multiple rounds of inference and frequent tool invocations can lead to sudden data floods. If the collection components experience lock contention, blocking, or unordered accumulation under high concurrency, it is easy to upgrade controllable performance fluctuations to full-link problems.
LoongCollector realizes low resource consumption and high throughput in high-concurrency scenarios through time-slice scheduling, lock-free design, high and low water level feedback queues, and persistent caching, ensuring that data is not lost, systems do not jitter, and business stability is maintained.
Flexible deployment and intelligent routing
Flexible deployment and intelligent routing capabilities determine whether this collection system can adapt to the continuously evolving AI engineering practices.
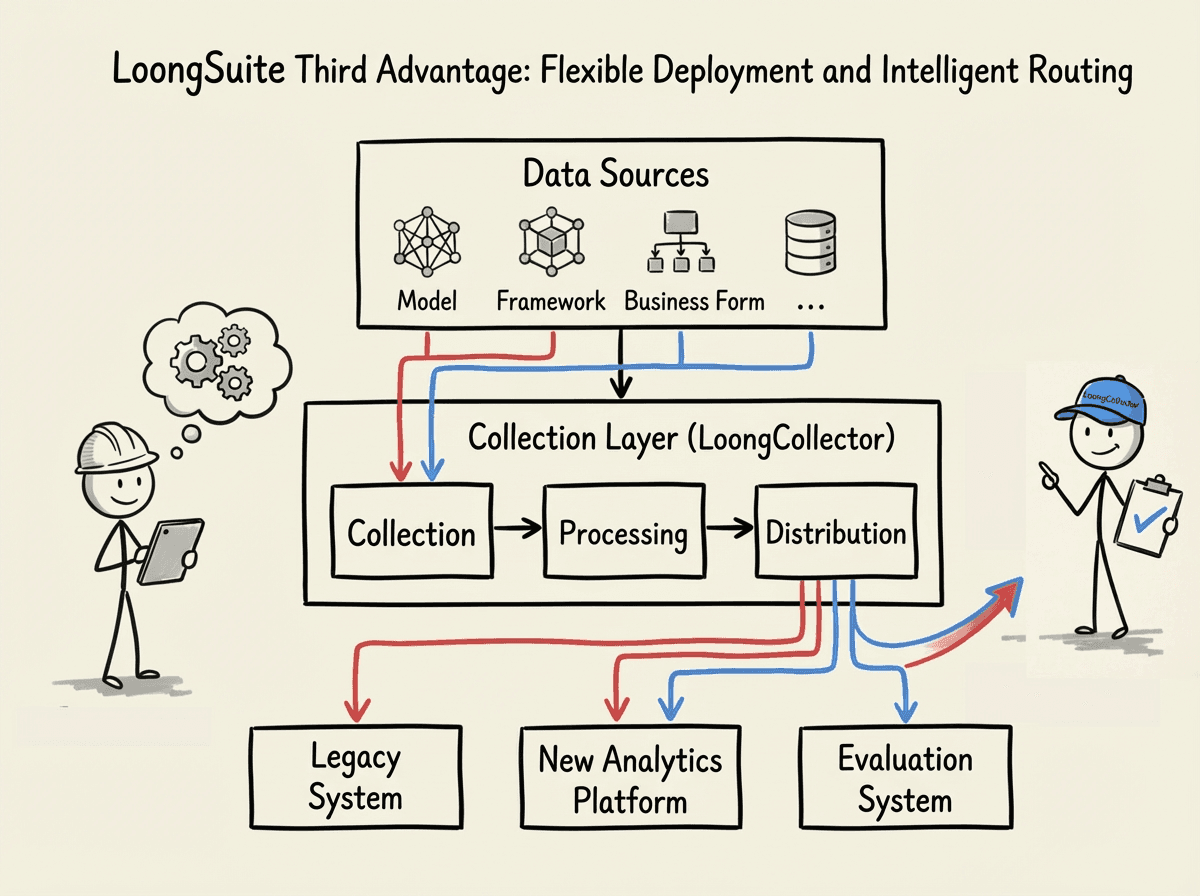
Observable systems are not built all at once. With changes in models, frameworks, and business forms, the value density and usage of data will continuously adjust. If the collection layer is strongly coupled with downstream storage and analysis systems, every adjustment means reconstruction and risk accumulation.
LoongCollector decouples collection, processing, and distribution through a modular architecture, allowing data from different sources and different semantics to undergo structured transformation at the collection layer and be routed to different downstream systems according to policies. This design enables engineering teams to introduce new analysis platforms or assessment systems without damaging existing systems, ensuring observability capabilities can evolve with Agent applications rather than becoming a bottleneck to innovation.
4. Why Open Source
In the age of AI, data collection is no longer just an "implementation issue," but an ecological problem.
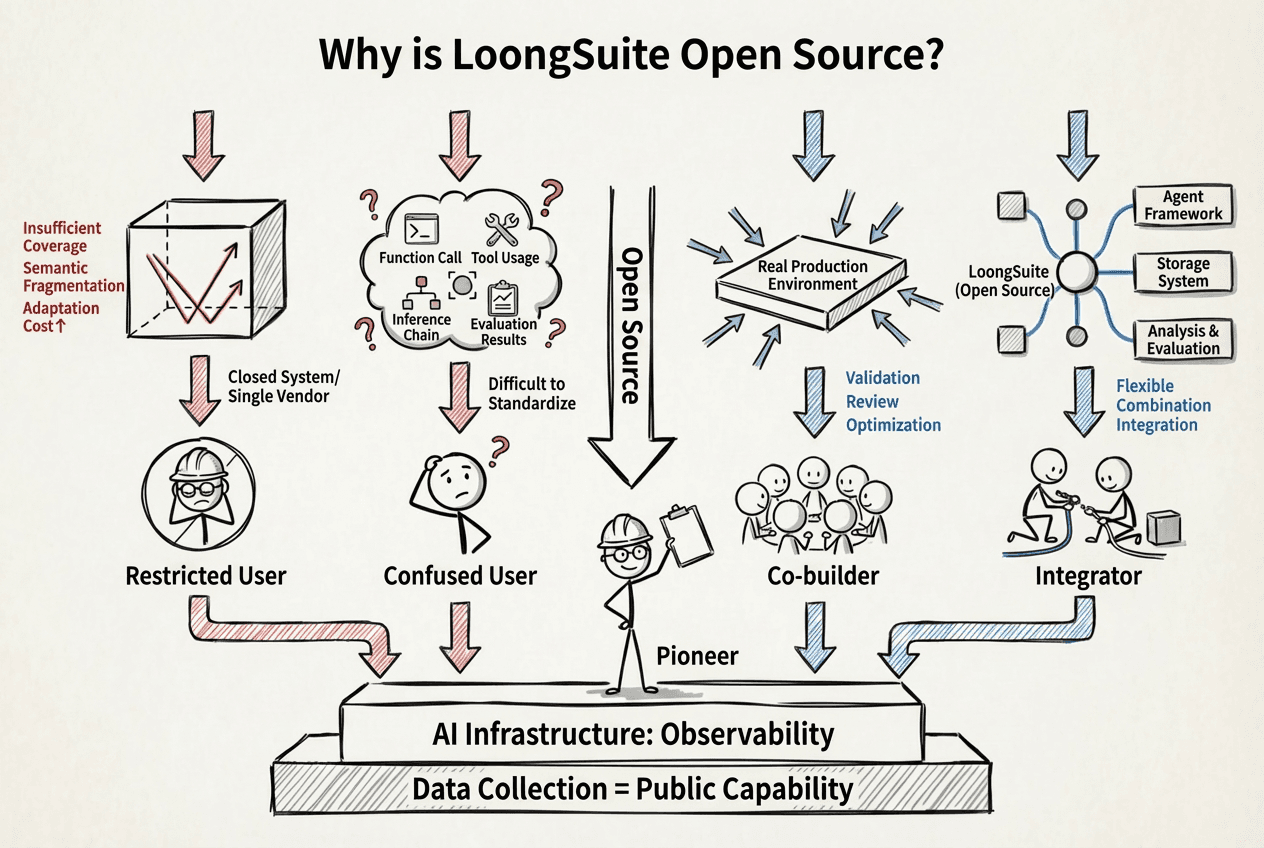
On one hand, the complexity of Agent applications is rapidly bleeding out. Whether it is Agents quickly assembled based on low-code platforms or complex systems carefully polished within high-code frameworks, their technology stacks, operating forms, and interaction modes are highly diversified. If data collection capabilities are encapsulated within a singular vendor or closed system, it inevitably faces issues of inadequate coverage, semantic fragmentation, and exponential increases in adaptation costs. For observability to truly become the infrastructure of AI, it must first become a public capability.
On the other hand, AI observability is forming a de facto consensus and technical standard within the industry. From OpenTelemetry's successful experience in the observable field, it can be seen that only through open sourcing can a maximum common denominator be formed in semantic specifications, data models, and collection methods, avoiding reinventing the wheel and preventing fragmentation. Especially in the Agent scenario, new signal types such as function calls, tool usage, inference chains, and evaluation results are emerging endlessly, and no single vendor can independently define a standard answer. Open source is the most pragmatic response to uncertainty.
From the engineering perspective, open source is also a long-term responsibility for performance and costs. Data collection is positioned at the bottom layer of the system, running on the critical paths of hosts, containers, and processes, and any additional overhead will be exponentially amplified. By open sourcing, LoongSuite can be validated, scrutinized, and optimized in a broader range of real production environments, making extreme performance no longer just a laboratory metric but an engineering reality that can continually converge in community co-construction.
More importantly, Alibaba Cloud does not wish for LoongSuite to be merely "another collector." Open sourcing it means it serves not just one platform or product but becomes a universal puzzle piece within the AI observability system: it can be integrated into different Agent frameworks and freely combined with various storage, analysis, and assessment systems, ultimately helping developers build a truly end-to-end, evolvable Agent governance system.
Therefore, open source is not the endpoint but a choice: choosing openness to exchange for standards, combating complexity through co-construction, and driving AI applications towards scaling and sustainability through engineering rationality. The open sourcing of LoongSuite is the natural result of this judgment.
References:
LoongSuite includes the following key components:
LoongCollector: universal node agent, which prodivdes log collection, prometheus metric collection, and network and security collection capabilities based on eBPF. https://github.com/alibaba/loongcollector
LoongSuite Python Agent: a process agent providing instrumentation for python applications. https://github.com/alibaba/loongsuite-python-agent
LoongSuite Go Agent: a process agent for golang with compile time instrumentation. https://github.com/alibaba/loongsuite-go-agent
LoongSuite Java Agent: a process agent for Java applications. https://github.com/alibaba/loongsuite-java-agent



